人类大脑有大约 **1000 亿个神经元**(神经细胞),每个神经元都能够产生电脉冲。这些神经元连接成复杂的网络,不同的连接方式会有不同的“权重”贡献。
**ChatGPT 的核心是神经网络,就是对理想人脑的模拟。**
ChatGPT 虽然看起来很复杂,但实际上涉及的最终元素和原理非常简单,就是一个由“人工神经元”构成的神经网络,每个神经元执行简单操作:**将一组数值输入与一定的权重相结合**。
ChatGPT 的原始输入是一个由数组成的数组,当 ChatGPT“运行”时,这些数会“依次通过”神经网络的各层,每个神经元都会“做好本职工作”并将结果传递给下一层的神经元。一切都是在网络中“向前馈送”的。
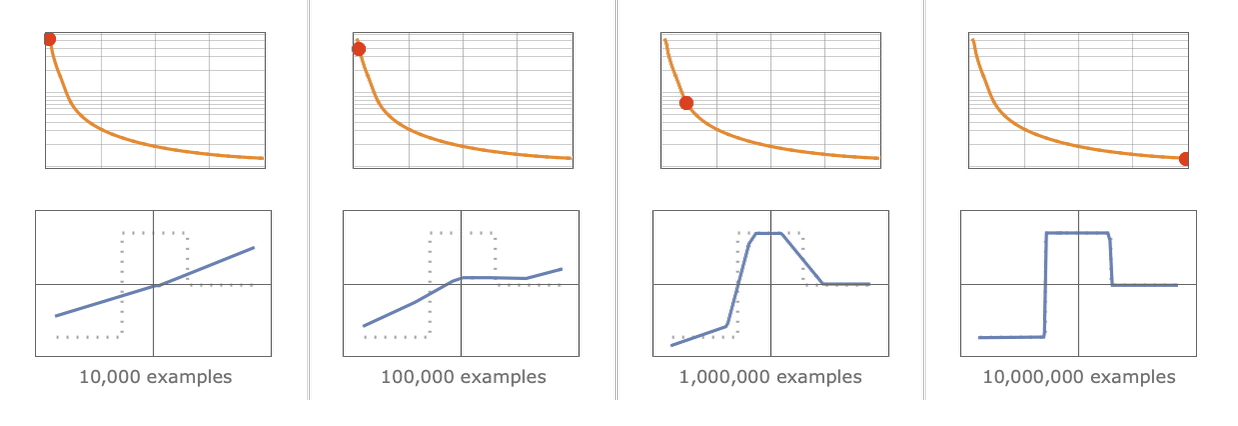
基本思想是提供大量的**“输入→输出”样例以供“学习”**(也就是训练),然后尝试找到能够复现这些样例的权重。
应该如何调整权重呢?基本思想是,在每个阶段看一下我们离想要的效果**“有多远”**,然后朝更接近该函数的方向更新权重。
如何衡量离目标“有多远”?用**“损失函数”**表示。
**学习的样本越多,损失就越少:离理想效果的差距就越小。**
为什么这么说?大多数情况下,神经网络的学问不是通过第一性原理推导出来,而是通过**“试错”**、并不断添加想法和技巧发现的,其中还有大量至今也无法解释原因。
——你就是知道,结果上看,是有效。
这也部分说明了为什么神经网络在过去的几十年里一直被冷嘲热讽。
因为每生成一个新的 token(词或者词的一部分),基本上都必须进行一次包含 **1750 亿个权重**的计算。
ChatGPT 总共有 1750 亿个连接,因此有 1750 亿个权重。需要认识到的一件事是,ChatGPT 每生成一个新的标记,都必须进行一次包括所有这些权重在内的计算。在实现上,这些计算可以“按层”组织成高度并行的数组操作,方便地在 GPU 上完成。
但是对于每个产生的标记,仍然需要进行 **1750 亿次计算**(并在最后进行一些额外的计算)。
因此,不难理解使用 ChatGPT 生成一段长文本需要一些时间。
当我们运行 ChatGPT 来生成文本时,基本上每个权重都需要使用一次。因此,如果有 $n$ 个权重,就需要执行约 $n$ 个计算步骤。
但是,如果需要约 $n$ 个词的训练数据来设置这些权重,那么可以得出结论:**需要约 $n \times n$ 个计算步骤来进行网络的训练。**
这就是为什么使用当前的方法最终需要耗费数十亿美元来进行训练。
神经网络的一个重要特征是,它们说到底只是在处理数据——和计算机一样。
神经网络的一个特点是,**“数据增强”**的变化不一定要很复杂才有用。例如,只需使用基本的图像处理方法稍微修改图像,即可使其在神经网络训练中基本上“像新的一样好”。另一个例子是,当人们在训练自动驾驶汽车时用完了实际的视频等数据,可以继续在模拟的游戏环境中获取数据,而不需要真实场景的所有细节。
——这是关于数据很有意思的点,因为有很多人讨论数据耗尽以后怎么办。
另外值得关注的点是:还可以将神经网络本身生成的数据用于训练神经网络,所谓**用 AI 训练 AI**。
训练神经网络很难,并且需要大量的计算工作。绝大部分工作是在处理数的数组,这正是 **GPU 擅长**的——这也是为什么神经网络训练通常受限于可用的 GPU 数量。
- **从实数到低精度数值:** 越来越清楚的是,重点并不是拥有高精度数值,即使使用当前的方法,**8 位或更少的数**也可能已经足够了。
- **渐进式网络重写:** 神经网络改进的是连接的强度(“权重”)。涉及渐进式网络重写的东西,可能最终会做得更好。
- **计算与内存一体化:** 当前神经网络训练大部分时间是“空闲”的,因为计算机的内存独立于 CPU(或 GPU)。如果能像大脑一样,让每个**“记忆元素”(即神经元)也是一个潜在的活跃的计算元素**,可能会更高效地进行训练。
——这也许为解决制约当前 AI 发展的最大瓶颈(算力)提供了可能的方向。
过去,我们认为计算机完成很多任务(包括写文章)在“本质上太难了”。现在我们看到像 ChatGPT 这样的系统能够完成这些任务,会倾向于突然认为计算机一定变得更加强大了。
**但这并不是正确的结论……**我们应该得出的结论是,(像写文章这样)人类可以做到但认为计算机无法做到的任务,在某种意义上**计算起来实际上比我们想象的更容易**。
ChatGPT 的基本概念相当简单:首先从互联网、书籍等获取人类创造的海量文本样本,然后训练一个神经网络来生成**“与之类似”**的文本。特别是,它能够从“提示”开始,继续生成与其训练数据相似的文本。
值得注意和出乎意料的是,这个过程可以成功地产生与互联网、书籍等中的内容“相似”的文本。ChatGPT 不仅能产生连贯的人类语言,而且能根据“阅读”过的内容来**“循着提示说一些话”**。
这表明了一些至少在科学上非常重要的东西:**人类语言及其背后的思维模式在结构上比我们想象的更简单、更“符合规律”。**
——这可能对于很多有意无意抱有人类中心主义的人来说,不是一件好接受的事情。
最近关于 AI 是否有意识、AI 能否取代人的很多争论,经常让我想起当年地心说、进化论出现时曾经有过的争论。